
Stable Diffusion - My One Year Review
Last Updated: 09/06/2023
Chronicling my first year of AI image generation, with Stable Diffusion

Matthew Piercey

The AI revolution is upon us! Well, at least more than it’s ever been. We finally have the computing power, the years of research, and the wealth of open-source software necessary to make Artificial Intelligence a viable solution to a huge array of problems.
Say what you want about it, but AI is here to stay. Personally, I’m paranoid wary enough to be cautious of it, but I think it’s a tool like any other. And I for one have had a lot of fun with it. Especially a little tool called Stable Diffusion. It’s been about a year since I first tried out SD, so I figured now’s as good a time as any to share some thoughts. And images. Because I think it’s a wonderful tool that has helped me express my creativity in ways I never thought possible!
I think it’s worth setting the stage, because there have been so many developments in this space in the last few months, it’s unreal. So, back in summer 2022, I was introduced to a little tool called DALL-E Mini (later Craiyon). I had heard about DALL-E, and that hype was building around the then-upcoming DALL-E 2. But I was more interested in Craiyon, since I had heard it was open-source. Personally, I can appreciate the technical achievement or utility of a given Software-as-a-Service, but I generally get way more excited when I can run something locally.
Anyway, here are some goofy images I generated with Craiyon, below.
Craiyon may be many things, but good at faces is not one of them
I got into Craiyon after 2kliksphilip’s video below. For context, this was the pinnacle of open-source, self-hostable AI image generation at the time. Let’s not forget how far we’ve come.
While we’re at it, kliksphilip is genuinely a great historian. His videos are like time capsules, from his coverage of the CoViD-19 pandemic in the UK, to the development of AI upscaling techniques.
OK, well other than being downright hilarious, and more than a bit disturbing, it didn’t look like AI image generation was there yet. Well, self-hostable AI image generation. Midjourney and DALL-E weren’t all that interesting to me, because I couldn’t run them on my own PC.
But then Stability AI dropped Stable Diffusion 1.4, and I got a lot more interested. Time to put that RTX 3080 Ti I had recently bought to good use!
I forget exactly when it was, since time has kind of become a blur for me lately, but it was some time in early September 2022 when I first downloaded Stable Diffusion 1.4. Back then, there was just a command-line interface, and it wasn’t very optimized.
After several hours of messing around with configuration, Python dependencies (oh, joy), and command-line arguments, I started getting some interesting images. It took a long time back then to generate just one 512×512 px image - about a minute per image on my machine, if I recall. But for the next couple of weeks, I played around with it from time to time. It was tough to get it to respond to more complicated text prompts, but I did my best to create some interesting scenes.
Here are the greatest hits from that time of experimentation. They were rather few and far between back then, but it was showing immense promise.












Last Man Standing
OK, so I was definitely seeing the potential of Stable Diffusion. But for the most part, it still felt like more of a novelty than anything else.
I had heard the rumours, that Stable Diffusion 1.5 was coming out. Part of me genuinely wondered if it ever would, or if it the public release of v1.4 was just a stunt to get more VC funding. But lo and behold, it eventually was released in October of 2022. And from then on, everything started to move a lot faster.
In the meantime, I was getting used to writing more complicated prompts - what some people now call prompt engineering. Although the “meta” has changed somewhat since then, most sufficiently-complicated prompts still look like “word salad” to me.
Case in point, this was the prompt for one of my first really unique generations:
anime illustration of unkempt tired sinister mesmerizing smiling conniving smirking evil sadistic cyborg cyberpunk female robotic vampire with large sharp pointy canine vampire fangs and teeth
Yeah, I know, I know. Looks like an AliExpress product listing. At least I’m basically a walking thesaurus, so I could come up with very specific words to “nudge” the prompt in certain ways. Here’s the result of that prompt:

I know it's kind of goofy, but I really like how this turned out
Huh, I thought at this point. I guess I can use SD to make character concepts, now. Little did I know, that was a breakthrough that would lead me down a rabbithole of experimentation and creative expression.
Oh, and around this time, I got wind of a new project which would become known as Automatic1111’s Stable Diffusion WebUI. To this day, it’s one of the leading graphical interfaces for Stable Diffusion, and I’ve had a ton of fun with it. You can check it out for yourself at https://github.com/AUTOMATIC1111/stable-diffusion-webui. Over the past year, it has gotten a ton of updates, extensions, and features. There are others, but I’ve had a lot of success with “Auto” as it’s called in SD enthusiast circles. Speaking of which, it was around this time I was also introduced to the Stable Diffusion community’s subreddit, at https://www.reddit.com/r/StableDiffusion/. There’s always something interesting there, from tutorials, to showcases of new tech, and lots and lots of generated images. Many of them memes and anime pictures, because this is Reddit we’re talking about. But anyway, I was finally getting the hang of this stuff, and I wanted to attempt something a bit more ambitious.
So, up until now I had been mostly working with txt2img (text to image). But I had heard that there was also a way to take an image, in addition to a text prompt, and generate a new image from that. For those interested in the tech behind it, Computerphile made an excellent video on Diffusion Models that’s worth checking out.
Anyway, long story short, you can feed it an image, along with a text prompt, and get back a modified version of that image. It’s as if Stable Diffusion sees the input image as a stage in the generation pipeline. And you can set the percentage of the way it thinks it’s there. So for instance, you could tell it that a given image is 85% of the way to the image you want, and it’ll do its best to fill in the details it thinks should be in the final image.
So, me being as bad at drawing characters as I’ve ever been, I fed it a sketch of Magenta, a character from a game I might make someday. Fair warning, it’s rough.

Hey, I warned you it was rough! Just you wait to see what it becomes...
Granted, my original pencil sketch didn’t look that bad. But I had to colour it in, or else Stable Diffusion wouldn’t know what to do with it. Nowadays there’s a method for running uncoloured sketches through SD, but that didn’t exist back in late September 2022. So I had to make do.
After a few attempts, and turning denoising up almost all the way (denoising is the property I was talking about above, where you basically tell Stable Diffusion how far along your image is, and how much “work” SD has to do to it). The more you turn up denoising, the more SD has to work with. But the further the final result will stray from your original prompt image. In this case, I was fine with that.
After a few attempts (OK more than a few, a few dozen) I got something pretty interesting. It was cut-off at the top and bottom, because I didn’t really know what I was doing back then. But in my mind, it was a very promising start.

Now we're getting somewhere. But there was still a long way to go.
Anyway, I ended up merging bits and pieces from different generations, into one image. The cool thing about img2img is that you can make a hodge-podge edit to an image, then SD will try to fill in the gaps, and make it look more seamless.
In the editing program Krita, I built up my ideal version of Magenta. Bit by bit, it was starting to come together. As I got something I liked, I ran it through SD again. I also ran it through an AI upscaler, Real-ESRGAN. I tried to strike a balance between re-processing the image to remove the seams left from my edits, and over-processing that would remove too much detail.
But first, let me explain another technique.
Now this one is a very interesting feature of SD, and many other AI image generators. It’s the process of generating part of an image, inside an existing image. Photoshop has had a basic version of this sort of thing for a while now, but SD’s inpainting was in some ways a step above. (Photoshop now has “Generative Fill”, which is basically their version of AI-assisted inpainting, but it didn’t back in September 2022).
So anyway, I wanted to give Magenta some khaki shorts. So I tried my hand at inpainting. I marked off the area I wanted SD to do the generation, and I gave it a prompt for just the area I wanted to be inpainted. The result really impressed me. because up until then I hadn’t seen something like that be so easy. Of course the pose was a bit off, but I was willing to settle for something closer.
And really, that became one of my key takeaways from my experimentation with Stable Diffusion. It’s all about getting things closer to the version you have in your head. In my opinion, you might get all the way, depending on the complexity of the image in your head, but you’re probably going to have to make a compromise with the AI. Remember, it’s only a tool.
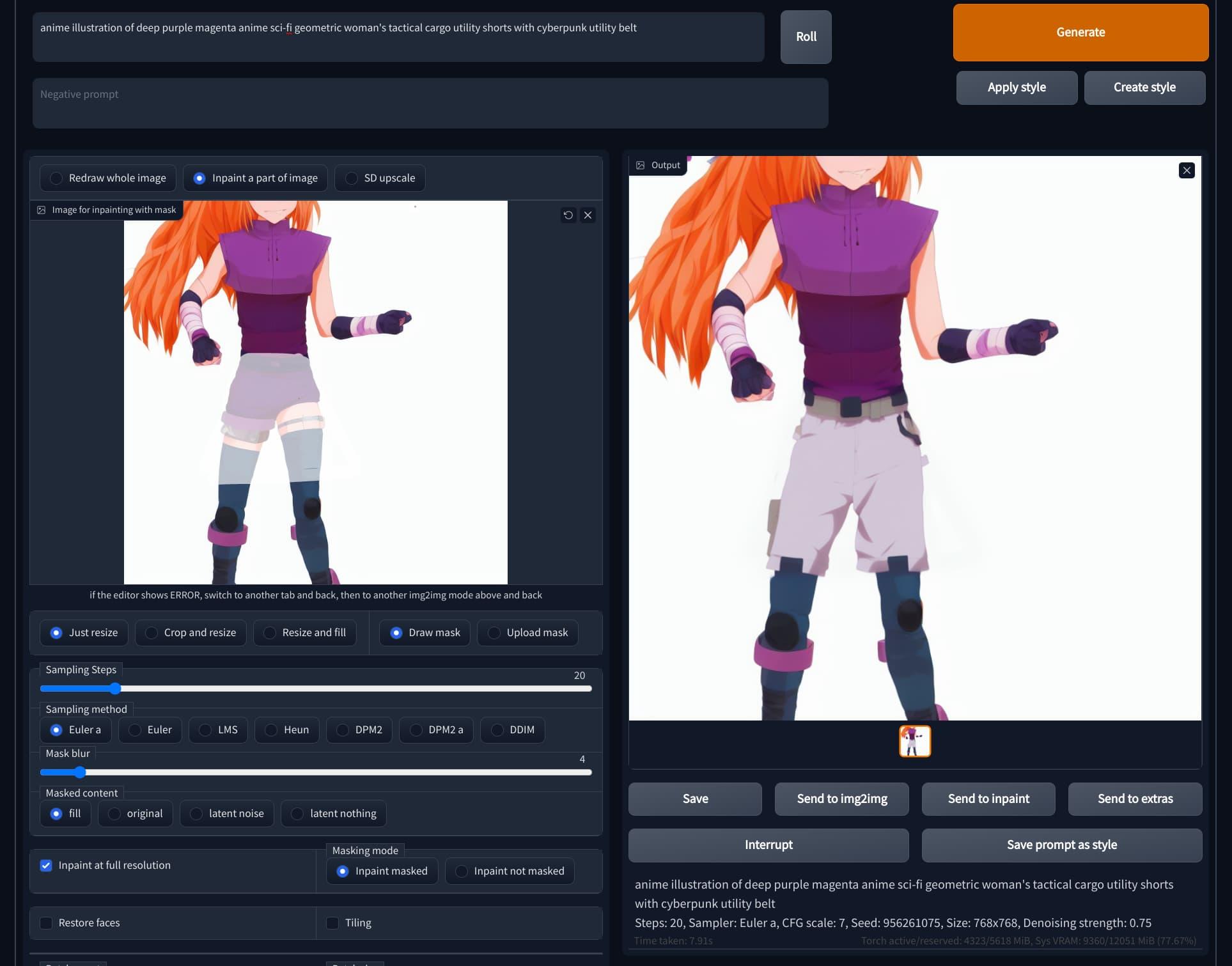
Now this is inpainting!
I continued with the AI-assisted image creation process. That’s one thing to note. At least the way I do things, it takes quite a bit of work to get what I’m looking for. Seldom is one AI generation enough, even after multiple attempts. I often have to edit the image and run it through one or several more times.
So while I understand at least the idea behind the anti-AI art movement, I personally can’t empathize with it. I don’t consider myself artistically gifted, but does that mean I shouldn’t be allowed to express my creativity in the way I really want to? Sure, I could spend years learning how to draw better, but my imagination is always going to outpace my hands in that regard. And I’m more than willing to leave that to people who are better at it, and who actually enjoy it.
I consider myself a writer, first and foremost. Writing stories, programs, essays, descriptions, blog posts… That’s my bread and butter, that’s how I express myself best. So I personally see Stable Diffusion as a great democratizer in a way. It opens the door for people like me to get visually creative in ways we otherwise never could be.
Listen, I’m all for hiring an artist if you can afford to pay them well. But in my experience, most of my ideas feel so dense and personal that it’s almost impossible for me to express them as a first or second draft, without the use of this technology, in a meaningful way to an artist, to get a result both of us can be happy with. But this way, now I finally can.
Like I said, AI image generation is about getting closer to what you’re looking for. Personally, I think it’s great for developing concept art. One of these days when I finally get around to making this game in earnest, I’m going to get some actual artists on board. Because I think a spark of genuine human artistry is what’s necessary for AI-assisted/inspired images to go all the way. But for now, while I’m still brainstorming and figuring things out, I’m fine with getting closer to visualizing the nebulous blobs of ideas in my head.
Tangent over, now back to the images.

Name's Magenta. Nice to meet ya!
It took several attempts to put a head on Magenta’s body. Admittedly, yeah, it still looks a bit like I took it from another image and put it on top. Especially the hair on top.
But hey, at least it’s pretty faithful to my original sketch that way. I added the smirk by hand, because it didn’t have a good enough facial expression. Again, this is a hodge-podge of about four images at this point, held together with duct tape and good vibes.
But that little peace sign she’s making with her hand, I didn’t ask for that. It just decided to give it to me. So I kept it. Thanks SD, very cool. Sometimes you just gotta roll with it. It might give you something you never asked for, but needed all along. Learn to enjoy the process.

The final product
It took a while, but in my opinion it was well worth the effort. I never could’ve drawn (and coloured) something like this by hand, but SD really pulled through.
Sure, it’s far from perfect. You could point out reasonable nitpicks for days, especially if you were to zoom in. But that’s not the point! This is a concept that existed only in my head, and was only made possible with the help of Stable Diffusion. You’ll note that it shares a lot of similarities with my original pencil sketch, below. But it’s a lot easier to suspend your disbelief, and imagine that this is an actual character, in my opinion. Although it doesn’t have all the detail I wanted. But again, it’s a start.
And let’s not forget, this was still the very early days of Stable Diffusion, at least for me. There was much more in store, and it all came sooner than even I could imagine.
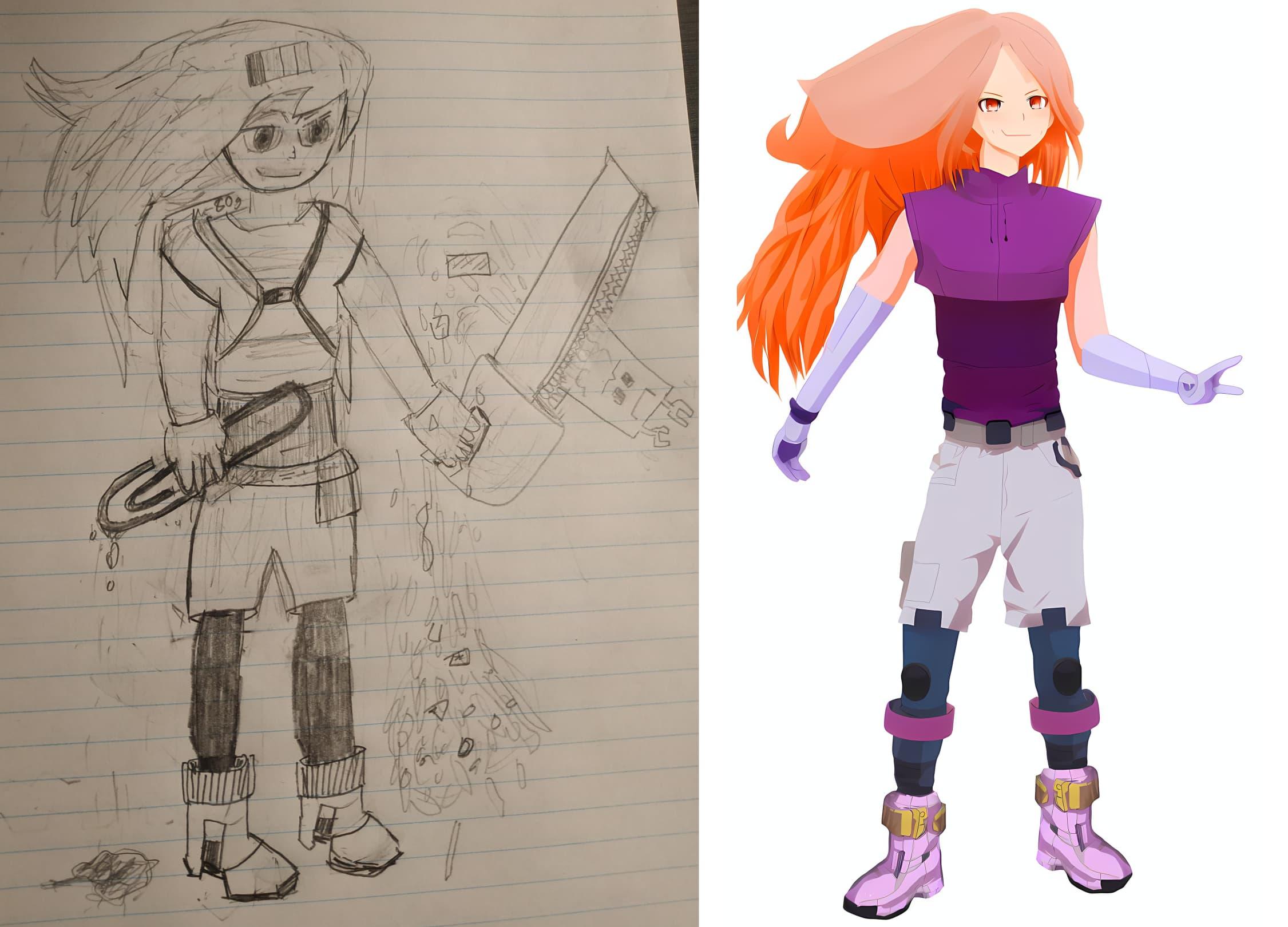
Before and after
Like I said, sometimes Stable Diffusion feels like it really has a mind of its own. Sometimes it goes off and adds a detail you weren’t expecting, or takes a prompt in a completely different direction when you change the seed.
It’s worth noting at this point that the seed, much like how Minecraft worlds are generated, lets you get a repeatable, predictable image. By changing the seed, sometimes you can get wildly different results, even with the same text prompt. And subtly changing the prompt but keeping the same seed can often help you refine an image, to tweak it in a given direction. To a point. There’s only so much you can do, before you have to just give up control a bit, and let the AI do what it does best.
But I don’t want to make it sound like giving up a bit of control is a bad thing. Because sometimes, just telling it to generate a batch of images with different seeds and the same prompt can give you an awesome surprise. Case in point, this image below.

This awesome shot worthy of a graphic novel came out of nowhere
The image below came from a session where I was trying to make an image of an old cyborg dude with a body made of wires. The generations before this one were mediocre at best, and didn’t feel like what I was trying to go for.
So I set SD to run in batch mode, with a new random seed each time, and came back to this. That’s when I learned to enjoy the process, because you might be given a gem if you’re patient enough. A good prompt always helps, and in my opinion is still the most important part, but sometimes you need to be open to the gifts of randomness.
Near the end of September 2022, I wanted to try to make some realistic human character portraits, for the game I’ll make someday.
Again, I’m a writer first and foremost, and I had already come up with some backstories for these characters. I felt like I knew them pretty well going into the generation process, but I kept an open mind, and was genuinely curious to see what SD would do with my descriptions of these characters. The results were, in my opinion, pretty impressive. Especially for the time - things have gotten quite a bit easier since, for reasons I’ll get into later.
Keep an eye on these five, you’ll see them again.






Samara
Now, obviously they’re not perfect. There are especially little imperfections in their clothes (like strange ties or missing buttons) and anybody showing hands or fists looks a bit off.
A major running joke, especially at the time, was how bad AI was at making hands. It definitely still struggles with it, but newer techniques and newer models have gotten a lot better. Just seems to be one of those things that isn’t easy to “fake it until you make it”. Since we humans are so good at recognizing imperfections in the human form. Maybe too good, but that’s neither here nor there.
You’ll also notice the “anime” (or at least cartoony) version of Mahira. That was an img2img result of running the same prompt through a model trained on anime pictures. While much more interesting models were on their way, it was an interesting taste of things to come. Namely, community-trained models can be tailored to specific styles, by being trained on different types of images. Through a process called “fine-tuning”, it’s possible to take the official “base” model from Stability AI, and tweak it, by training it to replicate the styles and features of custom images. At the time, this process was very difficult, and required a large amount of computing power. But things were about to change, drastically…
Anyway, it took a while for me to get all of those images generated. Each took at least a few hours of brainstorming, generating, tweaking prompts and settings, running images through upscalers or AI face enhancers like CodeFormer, and inpainting details (like the highlights in Mahira’s hair, and her scarf). But it was a fun creative exercise, that helped me better envision these characters I had been writing about.
It was now October 2022, and I felt like I was getting the hang of SD. So I wanted to attempt something a bit more involved.
I took another of my pencil sketches, coloured it in, and fed it through img2img. This time I made use of all the techniques I used when generating the image of Magenta. The final result was very much a composite image, but something I couldn’t have managed without Stable Diffusion’s help.


Before
This is Cyan, another character from my game concept. SD helped most with the basic shape of the helmet, the face, and the hair. But I added details like the colours and antenna on the helmet, and the pixel-art heart eyes. I also cleaned up some of the lines on the shirt.
Again, it’s not perfect, but it was a significant step above my original sketch. And yet closer to my original vision for the character.
It was now November 2022. Out of nowhere, a new anime-focused model was released. Called Anything V3, this model from a Chinese developer was, at least in my opinion, unlike anything we had seen before. Unlike some that had come before, this model made it very easy to create remarkably convincing anime-style images.
Some people were worried (rightfully so) that it might be a virus, since some antivirus softwares were flagging it. Eventually, the AI model community, led by Huggingface, would release the .safetensors format for storing AI models. Until then, we were mostly using .ckpt, which is technically far less secure than safetensors, and can contain arbitrary code. But that’s a story for another time.
The point is, I had to get my hands on this model. So I downloaded it and tried it out with a version of the prompt I used for Magenta. And I was very impressed with the results.

Animagenta
Pretty good, huh? It even got the peace sign gesture right, because this time I actually asked for it! If you look closely, you can still tell this is an AI-generated image. But personally, I looked at it and saw something super close to the image of Magenta in my head.
And here’s one more of my favourite generations from Anything V3. This is Mantissa, yet another character from my game concept.

Mantissa like I never saw her before
I was hyped to have been able to play around with this tech. It’s crazy how quickly familiarity can breed contempt, so I think it’s always a good idea to look back at just how far we’ve come.
It was now December 2022, and a couple of months since the release of Stable Diffusion 1.5. While 2.0 and 2.1 were eventually released, no official Stability AI model could outmatch 1.5, until the eventual release of Stable Diffusion XL 1.0. But let’s not get ahead of ourselves.
It was around this time, at least to my memory, that a lot of custom models started popping up. At the time, there were fine-tuned models like Anything V3, Dreambooth models (which were usually trained on a specific character or person), textual inversion embeddings (which were pretty good at transfering styles, but not so great for specific characters), and hypernetworks (which basically were for adding “post-processing” effects to images).
Around this time, a new site called CivitAI was gaining traction. There, users could post all manner of Stable Diffusion models, textual inversion embeddings, and hypernetworks. They have since branched out to many more Stable Diffusion-related things, and it has definitely become a hub of activity for the AI image generation community. But back in December 2022, there wasn’t the absolute wealth of custom models there is today.
But I was able to find some to play around with during this time. I tried out several textual inversion embeddings, a few hypernetworks, and a number of custom models.
One custom model was Corporate Memphis, which was trained on “soulless” flat corporate art. It was pretty fun to play around with.


Waltuh
Not to be outdone, a textual inversion embedding called Remix helped me make goofy action figures.


Get your Mini Mao's here, while supplies last!
In the last few weeks of 2022, I got some more interesting images of Cyan and Magenta, with a ton of personality. It was a great end to an exciting few months of experimenting with this brand-new tech. And I was so excited to see these characters who had before all but existed in my head, come to life.


Cyan, Late December 2022
To top it all off, I was able to help Josh make a marketing image, celebrating the launch of OverScore Nexus and our blog. Through inpainting, I was able to add some AI pizzazz to the top of the image. I think it turned out really well.
Speaking of Nexus, check out its project page to see how I incorporated AI-generated images into its design: https://overscore.media/projects/overscore-nexus.


Before
On New Year’s Eve 2022, I was able to use img2img to enhance an old drawing of MegaMan X that I made in 2014. Really felt like I came full circle here.


My original drawing - if anything I've gotten worse at drawing since
In mid-January 2023, I tried something I hadn’t attempted before. Training a model. I went for a textual inversion embedding model, since it was the smallest and easiest thing I could reliably train at the time. At least if my memory serves me correctly.
I fed Stable Diffusion a number of pictures of Magenta, to try to get it to “learn” her character design. The process of traning any Stable Diffusion model or embedding basically involves gathering up input images, and pairing them with textual captions. So you’re basically getting Stable Diffusion to reverse engineer images.
As a very basic example, you could feed it pictures of your pet dog. And each image could be given a caption, like “mydog on a beach on a sunny day”, “mydog eating kibble from a blue bowl”, “mydog with a tennis ball in his mouth”. Where “mydog” is the name of the embedding. And in each of the captions, you try to describe the parts of each input image that aren’t relevant to the character or thing or style you’re trying to replicate. For instance, if your dog had brown fur, you wouldn’t mention that in the captions. You want Stable Diffusion to be able to tell the difference between the concept of “mydog” and any other details in the reference images.
Then, once your embedding has been trained, you can tell Stable Diffusion to use it whenever you refer to “mydog” in a prompt. So you could ask it for a picture of your dog in a setting the input images never covered it being in. Like on the moon, or surfing, or in a hot air balloon.
It’s a process, and it takes some getting used to. Nowadays there are much better tools and tutorials out there for doing something like this. And better methodologies, like training LoRA’s instead of textual inversion embeddings, which are much easier to train, and can often retain more of the detail of the character or style you’re trying to train it on.
Anyway, I didn’t really know what I was doing at the time, so it could have gone better. But it was certainly an interesting experiment. The images my embedding generated were pretty low-quality compared to the images I trained it on. But it was a good learning experience, anyway. While I’ve gotten a bit better at training LoRA’s since, I’ve mostly stuck to text prompts for custom characters (i.e., not real people or existing characters in media that have a lot of well-photographed/drawn references).
And another very exciting technique for copying the style, features, or other characteristics of input images was just around the corner, anyway… But I’m getting ahead of myself again.



Weirdly got most of the details right, but the picture itself isn't great
Near the end of January 2023, I found a chibi art hypernetwork, that I got some decent results with. As I briefly mentioned above, a hypernetwork is like a “post-processing” layer. Stable Diffusion uses your text/image prompt as usual, then adds on the hypernetwork.
They seem to be best at style transfer. In this case, a pop art chibi-style cartoony look. It’s not perfect, but it certainly gives its images some personality.




Chibi-genta
In late February 2023, things started picking up. For one, a new model called Deliberate came to my attention. It claimed to allow for very intricate prompts, and seemed to be excellent for photorealistic or stylized character design.
I played around with it, and was very satisfied with its attention to detail. In this image, note the earrings, freckles, and texture on the clothes especially. Granted, it played it safe by not showing any hands in the picture, but still. Pretty good.

Deliberate Samara
Lest I be called out for giving my redhead characters too much time in the spotlight (because I’m totally not biased or anything), I was able to update some more character designs, using the Deliberate model.
I used close to the same prompts, but this time went for full-body portraits instead of just headshots. Because in the time since I first generated the images of these characters, it had gotten easier, faster, and less computationally-expensive to generate larger images.





Samara Revisited
But when it rains it pours in the world of technological developments, so I was soon introduced to a brand-new technique in March 2023.
What is ControlNet, you ask? Great question. Instead of just telling you, first yet me show you:



Yes, I know you've seen this image before. Wait for it...
Crazy, right? So ControlNet is basically a technique for transferring specific features of one image into another generated image. It allows you to control the neural network to “nudge” the resultant image in a given direction.
It’s honestly another rabbithole in and of itself, but there are a lot of different features you can transfer. From depth, to colours, to lines, to poses, and even using whole images as “references” to transfer their style completely. It’s an incredible tool, and I feel like it was a real gamechanger.
Back in the early days of just img2img, I could’ve really used something like this. Check out what it can do with illustrations:


The input image, generated with the Anything V5 model
It really is something else for enabling style transfer between different prompts or event different models. Because some models are better at lifelike images, some are better at illustrations, and some are better at simpler or more complex scenes.
So going back to what I’ve been saying, ControlNet is yet another tool to enable you to get closer to the image you have in your head. And a powerful tool at that.
And as if that wasn’t enough, by April 2023, I had gotten around to trying out LoRA models. Low-Rank Adaptations are basically mini-models that work alongside the main Stable Diffusion model, and can tweak its style, add support for custom characters, and basically do anything textual inversion embeddings can do - but better in most ways. Sure, they’re quite a bit bigger in file size than textual inversion embeddings (from a few megabytes to a couple hundred megabytes, whereas textual inversion embeddings are often in the kilobyte range). But LoRA’s definitely pack a punch.
Here are a few I experimented with. The coolest thing is that you can easily mix them, and you can adjust the “weights” so they each have more or less of an effect on the overall image. You can get really creative with these, really easily.




Figurine
So, it was now May 2023, and I wanted to attempt to use everything I had learned, and all the latest techniques and technology, to give my initial concept of Magenta another shot.
This time, I started from the initial AI-assisted hodge-podge image I put together with the help of img2img and a lot of trial and error. So at least I didn’t have to go back to square one, although with ControlNet it wouldn’t have been too bad.
But anyway, after using a new model, experimenting with different LoRAs, and using ControlNet to transfer features of my reference image, I ended up with something I’m pretty proud of. Sure, the pose and proportions are still a bit off. But if anything, that means it was a faithful transfer of my original drawing.

Magenta
So, yeah… All in all, I was really satisfied with what these new tools had allowed me to do. It was a winding road to get to where we’re at now, but in retrospect it all went so fast.
Sure, I’m leaving out a few parts to the story. Eventually Stable Diffusion XL 1.0 was released, and it was awesome in a lot of ways. But me personally, I’m still fine with Stable Diffusion 1.5, and the many custom models and LoRAs based on it. SDXL may be better at a lot of things, but 1.5 runs quite a bit faster on my machine. I don’t want to keep chasing this dragon, personally. And I don’t want to have to upgrade my GPU again, any time soon.
I’ve found a workflow, and a process that works really well for me. It lets me express my creativity in novel, meaningful ways, and I’m honestly super grateful that it exists. Sure, I’m still excited to see what’s next. Especially in the generated animation/video space, which is something I didn’t even touch on, because it’s a whole other ballgame.
From May 2023 onwards, in my mind at least there haven’t been many new gamechangers. But this tech is getting more and more mature, and the super-dedicated Stable Diffusion community continues to press forward into the great unknown.
Wow, if you’ve made it all the way to the bottom of this post, you’re a champ! Thanks for sticking around, and following my journey with this exciting emergent tech.
While I understand (at least to some extent) the concerns that many have addressed over this technology, I personally can’t see it as anything other than a tool. Like any tool, it can be used for good or for harm. And I definitely don’t think it’s going to replace artists - certainly not good ones - anytime soon. Never, at least in some way. Because there will always be the need for genuine, direct, unadulterated human creativity in this world. And whenever you have the chance to support a human artist, I say go for it.
Now, for anybody who opposes this tech on moral grounds, I understand and respect your opinion. I won’t deny you your right to be picky about the technology you use. But from my perspective, this has allowed me to have a lot of fun, at nobody’s expense, and has given me a unique, fulfilling creative outlet. I understand the limitations of this tech, and I for one vow to do my part to ensure it won’t be abused.
But I just can’t put into words how empowering and exhilarating this whole experience has been for me. And how many doors it’s opened in my mind. Because I really struggle with visualizing things, and I really just don’t have the fine motor control necessary to be as good of an artist as I wish I could be, no matter how much I practiced. I believe my time is far better spent in pursuit of what I am best at - as I believe everyone’s is. To each their own, I say.
Anywho, philosophy aside, thanks again for following along. Maybe you’ve learned a thing or two, but I hope you’ve at least had fun! If you want to see any of these characters again, you probably will in future blog posts. I’m still working on that game, and I’ll post about my gamedev journey someday, too.
But yeah, it’s been an exciting year for me, and I’m glad to have been able to share my experiences. Maybe we’ll catch up in another year’s time. It’s anybody’s guess where this tech is going to go from here, but I for one am chuffed to be along for the ride!

Generated September 3, 2023